Creating a Raspberry Pi cluster
Creating a Raspberry Pi cluster
First, let us get the why out if the equation.
Why would you want to do it?
I can’t speak for you. But I like tinkering with things. Lately, a lot of the Kaggle competitions appear to be dealing with relatively largish datasets. And I was starting to find it difficult to deal with it using Pandas. I initially tried generating a database from the data, and then going through it in chunks. It wasn’t pretty. And it wasn’t efficient. This convinced me that I should look into this Big Data business. Maybe Big Data had something going for it after all.
So I started learning Hadoop and Spark on Coursera. For some reason, although a virtual machine on a single node was the easy way out, I still was interested in performance. Hence, I wanted to check where the performance bottlenecks would me if we were to run things on a cluser. So I wanted to create my own cluster. Raspberry Pi’s just happen to be the cheapest option for this.
The Hardware
- Raspberry Pi 3 model B \(\times\) 3
- \(\mu\)SSD cards 64 Gb each
- A multi-port USB charger (so you don’t need single chargers for every Pi)
- USB cables to connect the charger to a Pi
- An \(\mu\)SSD card reader/writer for installing the operating system
- A wireless router (I used the one in the office)
- Keyboard, mouse, and a monitor to do the initial configuration on the Pi’s (I found some lying around in the office so I commandeered for a few hours)
Install the OS and Some Initial Configuration
This part is going to show you how to install the operating system, and set up secure shell access. Once that is done, there is no need of using the monitor, mouse and keyboard, because you can simply ssh into the system after.
Prepare the media and install the OS
1. Downloading the OS files
The OS files may be downloaded here. The Raspberry Pi has an excellent set of documentation for installing the OS on the SDD’s here. Mac-specific instructions may be found here. What follows is what worked for me.
2. Finding the name of the microSD card
Fod determining the name of the microSD card, use the df -h command before and after the memory card has been plugged in, as shown below:
$ df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1 465Gi 48Gi 417Gi 11% 858677 4294108602 0% /
devfs 220Ki 220Ki 0Bi 100% 760 0 100% /dev
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
After the memory card is plugged in,
| connecting the SD card to the computer |
|---|
 |
$ df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1 465Gi 48Gi 417Gi 11% 858681 4294108598 0% /
devfs 222Ki 222Ki 0Bi 100% 768 0 100% /dev
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
/dev/disk2s1 60Gi 8.9Mi 60Gi 1% 71 488121 0% /Volumes/Untitled
the extra disk /dev/disk2s1 appears. Now umount the disk and make sure that the disk is really unmounted. Do not disconnet the microSD at this point. You want to write the image to the disk.
$ sudo diskutil umount /dev/disk2s1
Password:
Volume (null) on disk2s1 unmounted
$ df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1 465Gi 48Gi 417Gi 11% 858748 4294108531 0% /
devfs 222Ki 222Ki 0Bi 100% 768 0 100% /dev
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
$
3. Write the disk image into the microSD card
Now we are going to write the disk image into the disk. We need to change the name of the disk so that we call the disk by its name rather than the load partition. This is done by converting the disk mount partition into a remote disk location. The nomenclature is as follow:
- The mount name is shown as:
/dev/disk<disk #><mont #>(e.g./dev/disk2s1) - Change the name to
/dev/rdisk<disk #>(e.g./dev/rdisk2)
Now, copy the disk image into the disk using the dd command.
$ sudo dd bs=1m if=2017-01-11-raspbian-jessie.img of=/dev/rdisk2
Password:
4169+0 records in
4169+0 records out
4371513344 bytes transferred in 184.578985 secs (23683700 bytes/sec)
$ df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1 465Gi 49Gi 416Gi 11% 858777 4294108502 0% /
devfs 223Ki 223Ki 0Bi 100% 772 0 100% /dev
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
/dev/disk2s1 62Mi 20Mi 42Mi 33% 0 0 100% /Volumes/boot
As you can see, the disk now is a boot disk. Notice however, that the size of the disk khas reduced significantly. from 60Gi to 62Mi. We shall take care of this later.
4. Eject the microSD card
sudo diskutil eject /dev/rdisk2
Repeat the process for all the cards that you have bought for this process.
5. Summary
The commands required for this are the following:
df -h # before mounting the microSD | The firt two commands just check the name of the
df -h # after mounting the microSD |disk. It should be the same for all disks
sudo diskutil umount /dev/disk2s1 # un mount the disk
sudo dd bs=1m if=2017-01-11-raspbian-jessie.img of=/dev/rdisk2 # write the disk image
sudo diskutil eject /dev/rdisk2 # unmount the disk again
Turon on your Raspberry Pi for basic configuration
1. Fill the entrire space of the microSD in the Raspberry Pi
For utilizing all of the disk space, we need to use the following command:
sudo raspi-config
This is going to bring up the following screen:
| config screen for the Raspberry Pi |
|---|
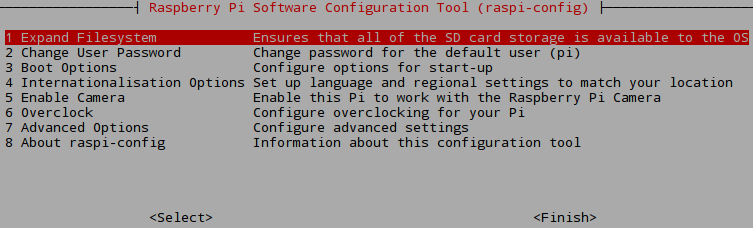 |
The first option is to expand the filesystem. Select this option and reboot. The result is the expanded filesystem shown below:
pi@raspberrypi:~ $ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 59G 3.6G 53G 7% /
devtmpfs 459M 0 459M 0% /dev
tmpfs 463M 0 463M 0% /dev/shm
tmpfs 463M 6.3M 457M 2% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 463M 0 463M 0% /sys/fs/cgroup
/dev/mmcblk0p1 63M 21M 42M 33% /boot
tmpfs 93M 0 93M 0% /run/user/1000
You can see that /dev/root is now 59G, approximately equal to the 60G size of the microSSD.
2. Install Java
Update all packages before installing Java. Then install Java.
pi@raspberrypi:~ $ sudo apt-get update
pi@raspberrypi:~ $ sudo apt-get install oracle-java8-jdk
In the operating system that I had installed, it turns out that Java was already installed.
3. Use static network addresses
Before Hadoop can be installed, the Raspberry Pi has to be set up so that one can use static network addressed. The information in this site was really useful. I followed the instructions exactly and things seemed to work. In summary the following files were changed:
/etc/wpa_supplicant/wpa_supplicant.conf
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
country=GB
network={
ssid="network name I am connecting to"
psk="network password"
key_mgmt=WPA-PSK
}
to
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
country=GB
network={
ssid="network name I am connecting to"
psk="network password"
proto=RSN
key_mgmt=WPA-PSK
pairwise=CCMP
auth_alg=OPEN
}
Reboot. Making these changes should still allow you to connect to the router without a problem. The next step is to connect to configure the Raspberry Pi so that it connects via a static IP.
For this, another file is changed: /etc/network/interfaces
From
## interfaces(5) file used by ifup(8) and ifdown(8)
# Please note that this file is written to be used with dhcpcd
# For static IP, consult /etc/dhcpcd.conf and 'man dhcpcd.conf'
# Include files from /etc/network/interfaces.d:
source-directory /etc/network/interfaces.d
auto lo
iface lo inet loopback
iface eth0 inet manual
allow-hotplug wlan0
iface wlan0 inet manual
wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
allow-hotplug wlan1
iface wlan1 inet manual
wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
to
## interfaces(5) file used by ifup(8) and ifdown(8)
# Please note that this file is written to be used with dhcpcd
# For static IP, consult /etc/dhcpcd.conf and 'man dhcpcd.conf'
# Include files from /etc/network/interfaces.d:
source-directory /etc/network/interfaces.d
auto wlan0
iface lo inet loopback
iface eth0 inet dhcp
allow-hotplug wlan0
iface wlan0 inet static
address 192.168.1.155
netmask 255.255.255.0
gateway 192.168.1.1
wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
iface default inet dhcp
allow-hotplug wlan1
iface wlan1 inet manual
wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
Note that we are using the static IP address 192.168.1.155 for this Raspberry Pi. It is important to change the address for the other Pi’s, so that they can individually be addressed.
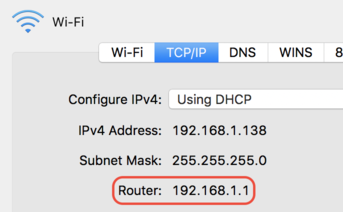
Note that you can get your router IP address from your network preferences on a Mac.
| connecting the SD card to the computer |
|---|
 |
Also note that the line address 192.168.1.155 will have to be different on each of your Pi’s. I have used the addresses
192.168.1.155,192.168.1.156, and192.168.1.157
For my 3 Pi’s. You can use whatever you want.
4. Change the hostname (Advanced Configuration)
The advanced configuration allows you to change the hostname of the pi. This is extreemly useful, as you will then no longer need to remember the pi addresses. You can simply use the names. What is more, when you configure Hadoop, it will be relatively easy to use these node names.
| hostname | IP address |
|---|---|
| node1 | 192.168.1.155 |
| node2 | 192.168.1.156 |
| node3 | 192.168.1.157 |
5. Enable ssh (Advanced Configuration)
Now you should be able to acceess the Raspberry Pi through your computer. You no longer need to have a screen sonnected to the Pi anymore. You can directly ssh in at will.
The default username is pi, and the default password is raspberry.
$ ssh pi@192.168.1.155 # ssh pi@node1 should also work
password: raspberry
Now that we can ssh into the different configurations, we don’t have to have a mouse, keyboard, and monitor attached to the Raspberry Pi’s anymore. We can setup all of the other configurations through the secure shell.
6. Summary
For basic configuration of the Raspberry Pi, we want to complete the folliowing tasks:
sudo raspi-config:- Increase the size of the available memory to fill the entire memory of the microSD
- Change the hostname
- Enabel
ssh
- Change the wireless options so as to use static IP addresses
Install Hadoop
Now we will go through the installation of Hadoop. For a multi-cluster system, it is preferable to have a separate user/usergroup allocated to Hadoop. The username will be hduser, and the usergroup will be hadoop. This user/usergroup will be present in all of the three Pi’s so that YARN can easily log into any of the machines and read/write files in a consistent manner.
1. Generate a usergroup and user for Hadoop
Before installing Hadoop,
pi@node1:~ $ sudo addgroup hadoop
[..................................messages truncated ..................................]
Done.
pi@node1:~ $ sudo adduser --ingroup hadoop hduser
[..................................messages truncated ..................................]
Enter new UNIX password:
Retype new UNIX password:
[..................................messages truncated ..................................]
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y
pi@node1:~ $
The passwords that I have entered are the following:
| hostname | IP address | password |
|---|---|---|
| node1 | 192.168.1.155 | pi1 |
| node2 | 192.168.1.156 | pi2 |
| node3 | 192.168.1.157 | pi3 |
Again, you can choose what you want …
2. Install Hadoop
This basically consists of downloading the compressed binaries, uncompressing them, and then coping them to a convinient location. Here are the steps …
# 1. Go somewhere
cd ~/
# 2. Download the compressed binary
wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
# 3. uncompress it in /opt/ <- a typical place to keep libraries
sudo tar -xvzf hadoop-2.7.3.tar.gz -C /opt/
cd /opt
# 4. Name it something appropriate and easy-to-remember
sudo mv hadoop-2.7.3 hadoop
# 5. Make hadoop the owner of the folder
sudo chown -R hduser:hadoop hadoop
Repeat this for all the three Pi’s.
Configure One of the Pi’s as a Single Node Cluster
Before moving ahead, we shall configure one of the Pi’s as a single node cluster. These are the main reasons behind it.
- A single cluser requires practically all of the configuration that is required for the multi-node cluster.
- Once you have configured a single node cluster, you can test it immediately.
- Finally, when the single node is working properly, you can simply copy entire configuration folders to the other nodes, and save yourself a ton of time in the configuration process.
So, lets begin the configurations:
1. Update /etc/bash.bashrc
Insert into /etc/bash.bashrc
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
export HADOOP_INSTALL=/opt/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib/native"
export HADOOP_HOME=$HADOOP_INSTALL
And make sure that the changes take effect …
make the changes take effect:
source /etc/bash.bashrc; source ~/.bashrc
2. Update paths in /opt/hadoop/etc/hadoop/hadoop-env.sh
Update the Hadoop environment variables in: /opt/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_INSTALL/lib/native -Djava.net.preferIPv4Stack=true"
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
3. Modify the file: /opt/hadoop/etc/hadoop/yarn-site.xml
All the tutorials had things a little different. After some experimenting, information from the following two sites worked best:
- Configuration: http://thepowerofdata.io/setting-up-a-apache-hadoop-2-7-single-node-on-ubuntu-14-04/
- What to change: http://www.widriksson.com/raspberry-pi-2-hadoop-2-cluster/
The things that we inserted into the YARN configuration file is shown below. The last two properties yarn.nodemanager.aux-services and yarn.nodemanager.aux-services.mapreduce_shuffle.class are not mentioned in the tutorials. Those were obtained from stack overflow answers, and inserted for basic MapReduce programs to work. I have no idea what they do.
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>768</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>64</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>256</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
4. Modify the file /opt/hadoop/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx204M</value>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>2</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>102</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx102M</value>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>128</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx102M</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.maps</name>
<value>2</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>2</value>
</property>
</configuration>
5. Modify the file /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hdfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:54310</value>
</property>
</configuration>
5. Modify the file /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>5242880</value>
</property>
</configuration>
6. Create HDFS folders
Hadoop will need some place that can be used for storing the HDFS files. We need to allocate a folder for this, and then format this.
sudo mkdir -p /hdfs/tmp
sudo chown hduser:hadoop /hdfs/tmp
sudo chmod 750 /hdfs/tmp
su hduser
hadoop namenode -format
7. Start a single-node Hadoop cluster
Now we are all set. Let us see if we can spin up Hadoop, and spin it down safely. Starting Hadoop requires that you start Hadoop first, and then start YARN.
# Starting hadoop
start-dfs.sh
start-yarn.sh
Once they are running, you should be able to check the process status of the running jobs …
hduser@node1:/opt/hadoop/etc/hadoop $ jps
2945 Jps
2648 NodeManager
2360 SecondaryNameNode
2153 DataNode
2540 ResourceManager
2044 NameNode
When you want to shut down the Hadoop cluster, you must first stop YARN, and then stop Hadoop.
stop-yarn.sh
stop-dfs.sh
8. Run a Simple MapReduce Job
Start up the Hadoop cluser, download some text files, and submit a mapreduce job for wordcount …
# Download the file
wget http://www.widriksson.com/wp-content/uploads/2014/10/hadoop_sample_txtfiles.tar.gz
# Unzip it
tar -xvzf hadoop_sample_txtfiles.tar.gz
# Put the files in HDFS
hadoop fs -put smallfile.txt /smallfile.txt
hadoop fs -put mediumfile.txt /mediumfile.txt
# Run the mapreduce program
cd /opt/hadoop/share/hadoop/mapreduce
time hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /smallfile.txt /smallfile-out
9. Summary
First a number of configuration files need to be changed. These are:
| folder | file | use |
|---|---|---|
| /etc/ | bash.bashrc | export environment variables |
| /opt/hadoop/etc/hadoop/ | hadoop-env.sh | export environment variables |
| /opt/hadoop/etc/hadoop/ | yarn-site.xml | block size configuration etc. |
| /opt/hadoop/etc/hadoop/ | mapred-site.xml | block and CPU configuration |
| /opt/hadoop/etc/hadoop/ | core-site.xml | hdfs folder location, server address |
| /opt/hadoop/etc/hadoop/ | hdfs-site.xml | blocksize |
As you can tell, most of these files are present in the /opt/hadoop/etc/hadoop/ folder. Later we shall directly copy all files from this folder and the bash.bashrc file to the other nodes using scp. Hence, there will be no need to configure the rest of the nodes anymore.
The Multi-Node Cluster
Now that we have a single node cluster, let us create multi-node clusters of all our Pi’s.
1. Generate HDFS folders in nodes 2 and 3
For these steps, we need to log in as the sudo user, pi@node2, etc …
sudo mkdir -p /hdfs/tmp
sudo chown hduser:hadoop /hdfs/tmp
sudo chmod 750 /hdfs/tmp
su hduser
hadoop namenode -format
Make sure that you wipe any junk information that is present in the hdfs folder
sudo rm -rf /hdfs/tmp/*
2. Generate the host list the master node in file /etc/hosts
In node1, update the file /etc/hosts to reflect the different IP addresses that will be used for the Hadoop
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#127.0.1.1 node1
192.168.1.155 node1
192.168.1.156 node2
192.168.1.157 node3
3. Add the following to the file /opt/hadoop/etc/hadoop/yarn-site.xml
For YARN, we need to add information for the resource manager. Do this in node1
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8040</value>
</property>
4. Change the following lines in /opt/hadoop/etc/hadoop/core-site.xml
Rather than using localhost we are going to explicitely mention that the core is node1. Do this in node1
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hdfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:54310</value>
</property>
</configuration>
5. Copy Configuration Files
Let us now create a multi-node cluster. Start by copying the configuration files into the other nodes …
Log into node2, and node3 as hduser in turn and copy …
scp hduser@node1:/opt/hadoop/etc/hadoop/* /opt/hadoop/etc/hadoop/
scp hduser@node1:/etc/bash.bashrc /etc/
# Make sure that you source the bash resource files ...
source /etc/bash.bashrc; source ~/.bashrc
6. Generate a file that shows the slave nodes [only in node1]
Generate the file /opt/hadoop/etc/hadoop/slaves and put in the nodes to be used as slaves …
node1
node2
node3
7. Set up password-less secure login
Now there is a problem with getting into the nodes. We want to be able to log in without a password. For doing that, we do the following on node1. Remember to log in into node1 as hduser, and remember that the password for node1 for hduser is pi1. You are supposed to have to do this on every node. For some reason, I have only needed to have done it on the master. It may be possible that when we are using Spark that accesses the accumulator in the master, this may be important.
ssh-keygen -t rsa -P pi1
ssh-copy-id hduser@node2
ssh-copy-id hduser@node3
8. Start the Multi-node Hadoop cluster
Log in as hduser and start the cluser as you normally would …